用于AI硬件加速器的基于電容器的架構(gòu)
很多文章的報道都是由微觀而宏觀 , 今日小編講給大家?guī)淼年P(guān)于用于AI硬件加速器的基于電容器的架構(gòu)的資訊也不例外,希翼可以在一定的程度上開闊你們的視野!y有對用于AI硬件加速器的基于電容器的架構(gòu)這篇文章感興趣的小伙伴可以一起來看看
IBM通過基于電容器的交叉點陣列用于模擬神經(jīng)網(wǎng)絡(luò) , 超越了數(shù)字技術(shù) , 在深度學(xué)習(xí)計算中顯示出潛在的數(shù)量級改進 。模擬計算架構(gòu)利用某些存儲設(shè)備的存儲能力和物理屬性 , 不僅用于存儲信息,而且還用于執(zhí)行計算 。這有可能極大地減少計算機所需的時間和能源,因為不需要在內(nèi)存和處理器之間穿梭數(shù)據(jù) 。缺點可能是計算精度降低,但是對于不需要高精度的系統(tǒng),這是正確的權(quán)衡 。
【用于AI硬件加速器的基于電容器的架構(gòu)】
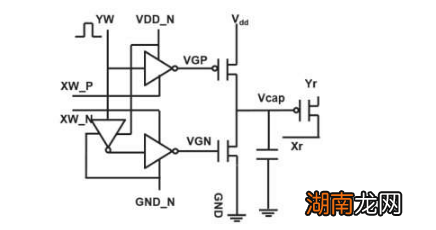
在模擬神經(jīng)網(wǎng)絡(luò)(NN)中,基于非易失性存儲器(NVM)的交叉點陣列已在推理任務(wù)方面取得了可喜的成果 。然而,對于NVM設(shè)備而言 , 難以對NN進行高精度訓(xùn)練,因為成功的訓(xùn)練取決于保持NN 權(quán)重的增量變化較小(需要大約1,000個更新狀態(tài))和對稱(以便使正負(fù)更新平均平衡) 。這些問題可以通過使用電容器來解決 。如果電子數(shù)量多,由于可以延續(xù)增加或減少電荷,因此可以實現(xiàn)模擬和對稱分量更新 。我們在2018年VLSI技術(shù)研討會上提出了一種用于模擬神經(jīng)網(wǎng)絡(luò)的基于電容器的交叉點陣列 。新的架構(gòu)實現(xiàn)了分量更新的對稱性和線性記錄 。
圖1顯示了基于電容器的交叉點陣列的單位單元示意圖 。關(guān)鍵組件是連接到讀出場效應(yīng)晶體管(FET)的電容器 。電容器上的電荷代表突觸權(quán)重,電容器通過兩個電流源FET充電和放電 。圖2分別顯示了十個周期的400個正更新,然后是400個負(fù)更新,分別測量了一個單元的讀出FET的電導(dǎo)變化和相應(yīng)的電容器電壓 。圖3比較了基于電容器的模擬突觸與其他NVM技術(shù)的實驗非線性更新因子 。基于電容器的單元電池提供了迄今為止證明的最佳對稱性和線性 。圖4演示了在2×2陣列上的并行權(quán)重更新 。

即使電容器易失,也可以在分量更新過程中補償泄漏 。由于訓(xùn)練反復(fù)進行前,后和權(quán)重更新循環(huán) , 因此前一個循環(huán)衰減后的權(quán)重將用于下一個循環(huán)的訓(xùn)練并得到更新 。因此,不需要故意的刷新周期 。我們使用完全連接的網(wǎng)絡(luò)測試了保留時間對訓(xùn)練的影響 。它具有一個輸入層,兩個隱藏層和一個輸出層(圖5),并通過隨機梯度下降和反向傳播在MNIST數(shù)據(jù)集上進行了訓(xùn)練 。假設(shè)每層的訓(xùn)練周期長度(向前+向后+更新)為200 ns,并且突觸權(quán)重隨RC時間常數(shù)τ衰減,我們發(fā)現(xiàn)當(dāng)τ> 106×訓(xùn)練周期時 , 電容器電荷損耗對訓(xùn)練精度的影響可以忽略不計長度(圖6) 。我們還測試了卷積網(wǎng)絡(luò)的保留時間要求 。我們的測試網(wǎng)絡(luò)有兩個卷積層,兩個卷積層和兩個完全連接的層(圖7) 。由于卷積層中的分量分配(重用),因此對于卷積層的保留要求卷積神經(jīng)網(wǎng)絡(luò)(CNN)大約大600(圖8) 。
對于完全連接的和卷積神經(jīng)網(wǎng)絡(luò),我們估量了這種基于電容器的陣列的可擴展性與泄漏的函數(shù)關(guān)系(圖9) 。圓形數(shù)據(jù)點表明,電容器隨傳輸晶體管泄漏呈線性比例變化 。方形數(shù)據(jù)點表明,當(dāng)泄漏較大時,電池面積由電容器決定;當(dāng)泄漏電流較小時,該區(qū)域?qū)⒂蓡卧械腇ET支配 。對于具有1 fA /單元泄漏的DRAM技術(shù),對于完全連接的神經(jīng)網(wǎng)絡(luò),電容器<1fF /單元需要電容器,而CNN則需要?100 fF /單元 。對于更大的輸入和更多層的可伸縮性需要進一步研究 。即使在輸入變大時可能需要更大的電容器,我們的初步結(jié)果(將要公布)表明該網(wǎng)絡(luò)/算法優(yōu)化可以減少電容器需求 。
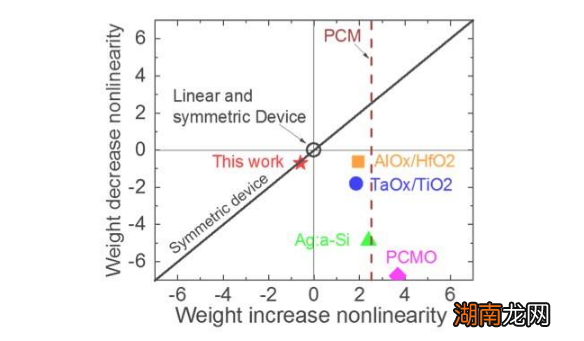
IBM現(xiàn)在正在研究具有優(yōu)化模擬行為的新型理想內(nèi)存 。由于已有技術(shù)和工藝可用,這些電容器將同意 加快模擬AI內(nèi)核的實現(xiàn) 。
除了我們的電容器方法外,IBM正在探究用于模擬存儲器和計算的其他新穎元件,例如相變存儲器(PCM)和電阻式RAM(RRAM) 。這些元素在細(xì)胞面積,保留 , 對稱性和成熟度方面有所不同 。模擬加速器是IBM Research AI的AI硬件加速器產(chǎn)品線的一個組成部分 。開辟流程首先要從現(xiàn)有的GPU加速器中獲得最大收益,然后是利用近似計算的創(chuàng)新數(shù)字AI內(nèi)核 。
猜你喜歡
- 黃色表情 黃色表示禁止停止用于禁止標(biāo)志
- Plannuh籌集了400萬美元 用于擴展AI驅(qū)動的營銷
- ?Method360啟動數(shù)據(jù)管理加速器
- 主要用于低排量汽車嗎 92號汽油適用于什么車
- Tobii的眼動追蹤I系列具有第二個用于面對面交流的屏幕
- 蘋果手機硬件檢測 蘋果手機硬件檢測app
- 谷歌發(fā)布了全新的谷歌Pixel 3a/3a XL以及一系列全新的軟硬件
- 超敏感設(shè)備用于回收原子
- 新型晶體將電子限制在一維空間 可用于開發(fā)自旋電子器件
- Ezoic籌集了3300萬美元用于優(yōu)化人工智能網(wǎng)站